เมื่อกี้ Alibaba ปล่อย Qwen3.5-Omni ออกมาเงียบๆ…


Qwen3.5-Omni คือโมเดล AI จาก Tongyi Lab (Alibaba) ที่รับและเข้าใจได้ทุกอย่างพร้อมกันเลย ไม่ว่าจะเป็น ข้อความ รูปภาพ เสียง และวิดีโอ แบบ native ไม่ใช่แปะ plugin ทีหลัง และมาใน 3 ขนาด คือ Plus (เต็มประสิทธิภาพ) Flash (เร็ว) และ Light (เบา)
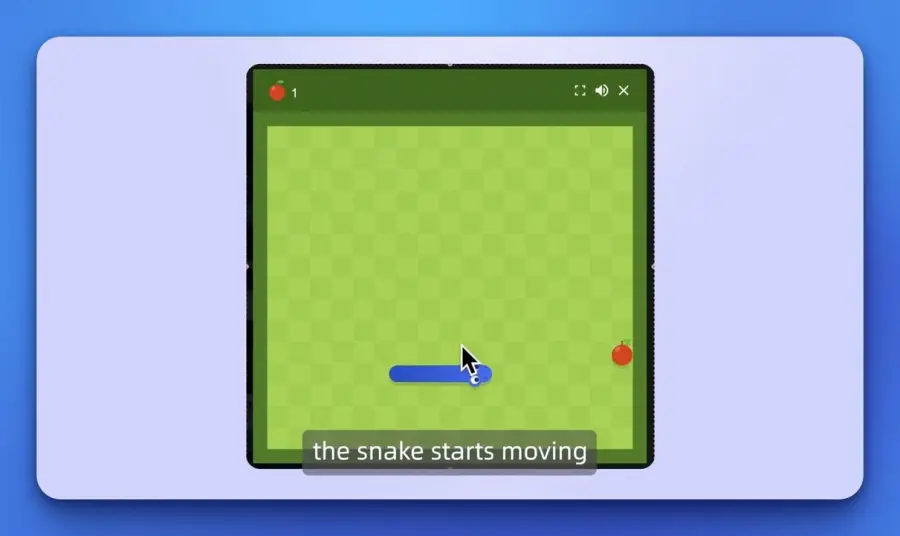
ฟีเจอร์ที่ทำให้คนในวงการตื่นเต้นมากที่สุดคือ Audio-Visual Vibe Coding พูดคุยกับกล้อง อธิบาย idea ที่อยากได้ แล้วโมเดลสร้าง prototype ที่ใช้งานได้จริงออกมาเลย เช่น Snake game พร้อมธีมและเสียง แบบ real-time แก้ไขต่อเนื่องได้ ไม่มีโมเดลไหนทำแบบนี้ได้ชัดขนาดนี้มาก่อน
Real-time voice interaction ก็ดีขึ้นมากครับ พูดแทรกได้แบบมนุษย์ (Semantic Interruption) มีระบบตัดเสียงรบกวน ควบคุม emotion ของเสียงได้ และยังมี Voice Cloning คืออัปโหลดเสียงตัวเองให้ AI พูดเหมือนเราได้เลย
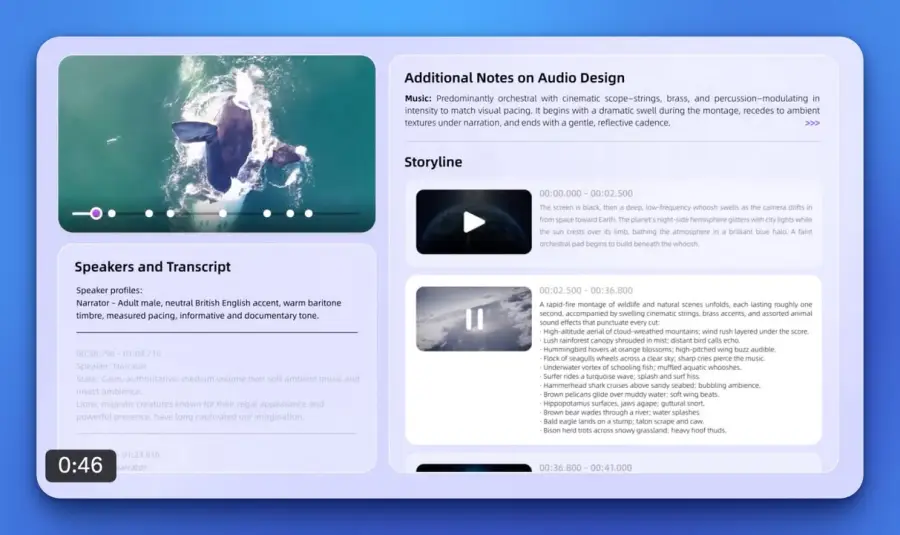
ฝั่ง performance ค่อนข้างน่าประทับใจ รองรับ audio ยาวกว่า 10 ชั่วโมง วิดีโอ 400+ วินาที context 256K tokens รับภาษาพูด 113 ภาษา/สำเนียง (รวมไทยด้วย) และใน benchmark 215 subtasks ด้าน audio-visual ชนะหรือเทียบเท่า Gemini 1.5 Pro
เรื่องราคาถือว่าถูกมากเมื่อเทียบกับตลาด ใช้ฟรีได้ที่ chat.qwen.ai ส่วน API อยู่ที่ประมาณ $0.1–0.5 USD ต่อล้าน input tokens ซึ่งถูกกว่า GPT-4o หรือ Gemini อยู่หลายเท่า เหมาะมากถ้าจะเอาไปต่อ production จริงจัง
ข้อด้อยตอนนี้ที่พอสังเกตได้ คือยังไม่ generate ภาพหรือวิดีโอออกมาได้ (รับเข้าได้แต่ output หลักคือ text + เสียง) weights ยังไม่ open เต็ม และรีวิวจากผู้ใช้จริงยังน้อยมากเพราะเพิ่งออกวันนี้เลย
สำหรับใครที่ทำ content, voice agent, meeting summarizer หรืองานที่ต้องยำทุก modality เข้าหากัน ผมว่าตัวนี้คุ้มมากที่จะลองก่อนตัวอื่น โดยเฉพาะเรื่องราคาที่ถูกกว่าชัดๆ อยากลองโยน Video เข้าไปทำ Flow เช่นสรุปคลิปไรงี้ ขอเทสก่อน
ลองเล่นได้เลยที่ chat.qwen.ai (ฟรี)

อยากใช้ AI กับงานจริงเป็นระบบ?
เรียน Claude Method — วิธีคิดและลงมือใช้ Claude/AI กับงานจริง ตั้งแต่วันแรก
📍 โพสต้นฉบับบน Facebook: AI กับ Peesamac