เพิ่งเจอโพสต์ สุดเจ๋งและละเอียดมาก บน X จาก Ryan Wiggins…

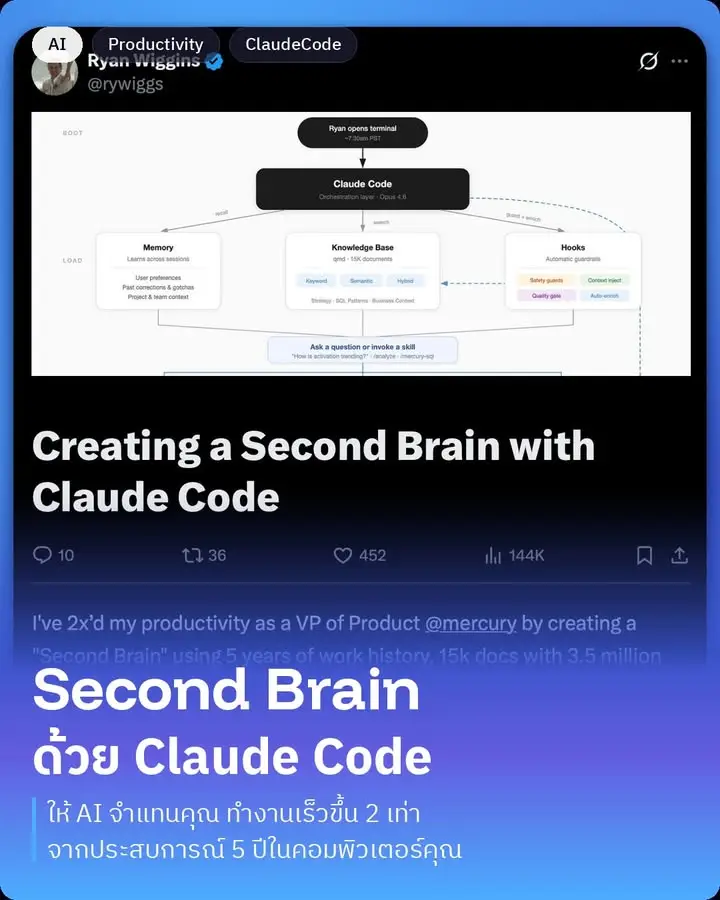
โพสต์นี้ได้รับ engagement สูงมาก (views กว่า 141,000) เพราะเขาบอกวิธีทำแบบ step-by-step จริง ๆ ไม่ใช่แค่แนวคิดลอย ๆ ผมเลยอยากมาเล่าให้ฟังแบบละเอียดยิบตามที่เขาอธิบายเลยนะครับภาพรวมที่เขาทำรวบรวมเอกสารการทำงานกว่า 15,000 เอกสาร รวม 3.5 ล้านคำ
ระบบรันแบบ local บนเครื่องตัวเองทั้งหมด
เชื่อมต่อและใช้งานร่วมกับ Claude Code (LLM) ทุกครั้งที่ใช้งาน
ระบบจะ อัปเดตและฉลาดขึ้นเรื่อย ๆ ทุกวัน (ไม่ใช่ static)
เขาทำงานเป็น VP of Product มานาน 5 ปี ที่ Mercury (บริษัท fintech) จึงต้องเข้าประชุมเยอะ ใช้หลาย tool (Linear, Slack, Notion, data analysis) และเป็นเหมือน “walking encyclopedia” ของบริษัทตั้งแต่ปี 2021 แต่ workload หนักขึ้นทำให้จำทุกอย่างไม่ไหวแรงบันดาลใจมาจากโพสต์ต่าง ๆ บน X เช่น QMD (local vector search) ของ @tobi
, Claude Code Hooks, Agent Teams จาก GasTown/OpenClaw, MCPs/CLIs, และแนวคิด “writing for AI” จาก Tyler Cowen
ขั้นตอนการสร้าง Second Brain (ใช้เวลาแค่ไม่กี่ชั่วโมง)
1. Prep work (~1-2 ชั่วโมง)
ดาวน์โหลดเอกสารทุกอย่างที่เคยสร้างที่บริษัท + เอกสารเกี่ยวข้อง เช่น product strategy, analysis, retro, reflection on execution ฯลฯ
→ ใส่ในโฟลเดอร์ชื่อ “raw data” แล้วใช้ QMD (local vector search) index ข้อมูลทั้งหมดบนเครื่อง
เขาทดสอบทันทีด้วย Claude Code ถามคำถามสุ่ม ๆ เกี่ยวกับความทรงจำและ insight แปลก ๆ
ผลลัพธ์ดีจนตกใจ โดยเฉพาะการแนะนำหนังสือที่ตรงกับตัวเขามาก (spooky good)
คำแนะนำสำคัญที่สุดจากเขา: Test ทุกขั้นตอน! อย่าเพิ่ง hill climb โดยไม่เช็ค
2. Train my brain + เชื่อมต่อเครื่องมือ (~2 ชั่วโมง)
เขาทำ 3 สิ่งหลัก:
Explain myself: เขียนไฟล์ me.md อธิบายตัวเองแบบละเอียด (งาน + ชีวิตส่วนตัว, เป้าหมาย, performance reviews 5 ปีล่าสุด, personal priorities)
→ ส่วนที่น่าอายที่สุดคือ ระบบชี้ให้เห็นว่าเขาทำ strategic mistake เดิมซ้ำ ๆ มานานหลายปี ตามที่ตัวเองเคยเขียนใน performance review และกำลังทำผิดซ้ำในสัปดาห์นั้นเลย!
Distill the data: ใช้ Agent Team (swarm) มาสรุปข้อมูลจาก me.md + raw data สร้างโฟลเดอร์ context.md
→ สรุป main themes ที่เคยทำงาน, ประวัติที่มา (sourced), key lessons ที่เรียนรู้
Connect tools: เชื่อมต่อ tool ที่ใช้ประจำ (Google Docs, Linear, Notion, Metabase)
ส่วนใหญ่มี connector ใน Claude Code หรือ MCPs/CLIs แล้ว ถ้าไม่มีก็สร้าง custom skills ที่เรียก API โดยตรง (เช่น run query สำหรับข้อมูลเฉพาะ)
3. Wire it up (<1 ชั่วโมง)
ใช้ Hooks จาก Claude Code (โดยเฉพาะ UserPromptSubmit hook)
ทุกครั้งที่พิมพ์ prompt → ระบบจะใช้ QMD ค้นหา names, topics, เอกสารที่เกี่ยวข้องโดยอัตโนมัติ แล้ว inject เข้าไปใน prompt ทันที
ระบบค้น 2 แบบ:
vsearch (semantic/vector search): เข้าใจความหมาย เช่น พิมพ์ “How's the funnel performing?” ก็เจอเอกสารเรื่อง conversion rate แม้จะไม่พูดคำว่า “funnel” โดยตรง
BM25 (keyword search): จับ proper nouns, acronyms, ตัวเลขเฉพาะ ที่ semantic อาจพลาด
หลังจาก inject context แบบนี้ คุณภาพของคำตอบดีขึ้นชัดเจน เขาเริ่มใช้ jargon แบบ lazy ได้เลย เพราะระบบเสริมบริบทให้อัตโนมัติ4. Let it learn (ทำให้ระบบพัฒนาตัวเองต่อเนื่อง)
แรงบันดาลใจจาก GasTown/OpenClaw ที่อัปเดต memory .md file เอง เขาจึงทำแบบเดียวกันกับ 3 ช่วงเวลา:Per session: สร้าง skill “/learn” ที่สรุปการสนทนา, งานที่ทำ, แล้วอัปเดตไฟล์ .md อัตโนมัติ (ช่วยมากกับ MCPs ที่ error บ่อย → ครั้งต่อไป prompt ดีขึ้น)
Per day/week: เช้า ๆ มี chron job สร้าง daily brief (สรุปสิ่งที่จะเกิดวันนี้ + context จาก knowledge base) แล้วอัปเดต memory ความคืบหน้า
End of Month: สัมภาษณ์ตัวเองกับ Claude ว่าเดือนนี้ตั้งใจทำอะไร, เป็นจริงอย่างไร, อะไรดี/ไม่ดี, เดือนหน้าจะปรับยังไง
ผลลัพธ์ในชีวิตจริง (เขาบอกว่า 2x productivity จริง)
Recall speed: หาข้อมูลเร็วสุด ๆ (needle in haystack ในไม่กี่วินาที) ทุกงานเริ่มจาก Claude Code session
No more meeting prep: วันเริ่มด้วย summary อัตโนมัติ (ประชุม, Linear updates, GitHub, Slack ที่ยังไม่ได้ตอบ) เข้า 1:1 แค่ prompt 1-2 ครั้งก็พร้อม
Never miss action item: ท้ายวันถาม “is there anything I forgot to do today?” มันจะหา interaction ที่ลืมปิดได้เกือบทุกครั้ง (cross-tool synthesis แรงมาก)
Realtime feedback: ระบบรู้ performance reviews เก่า จึงเตือนเมื่อเขากำลังทำพฤติกรรมเดิมที่เคยถูก feedback (feedback จากเจ้านายปกติได้แค่ bi-weekly แต่ระบบทำ real-time)
Proactive explorer mode: ระบบเริ่มคิดและทำ autonomous research ให้เอง โดยใช้ความรู้ 5 ปี + tools ทั้งหมด (เขาต่อยอดด้วย Chron jobs, Agent Swarm, @karpathy’s AutoResearch, Lenny’s interview archives ฯลฯ)
เขายังแชร์รูป ภาพ Second Brain ที่ระบบวาดให้เอง (น่ารักและน่าประทับใจ) และ prompt ที่ใช้ได้จริง (ใครอยากลองก็ copy ไปใช้ได้)
เรื่องอื่น ๆ ที่เขาตอบใน replies
ค่าใช้จ่าย: ปัจจุบัน $1-2k/เดือน เพราะ chase frontier และใช้ Opus 4.6 บ่อย ๆ แต่ถ้าใช้ปกติทั่วไป น่าจะต่ำกว่า $500/เดือน
Privacy & Security: ลบเอกสาร sensitive จริง ๆ ออกก่อน
ใช้ local LLMs obfuscate ข้อมูล (ลบ/พราง PII, emails, addresses)
มี security hook ลบ PII ก่อนส่งให้ Claude
สำหรับ data analysis ใช้แค่ aggregate data เท่านั้น
เขาเชื่อใน terms ของ Anthropic (ไม่ store/train) แต่ก็ระวังเรื่อง Enterprise agreement
รู้สึกว่านี่คือหนึ่งในโพสต์ AI Productivity ที่ละเอียดและลงมือทำได้จริงที่สุดในช่วงนี้เลยครับ โดยเฉพาะคนที่ทำงานกับข้อมูลเยอะ ประชุมบ่อย หรืออยากให้ AI ช่วยจัดการ “สมอง” ให้มีประสิทธิภาพสูงขึ้นแบบยั่งยืนลิงก์โพสต์ต้นฉบับ: https://x.com/rywiggs/status/2044448092477661638
อยากใช้ AI กับงานจริงเป็นระบบ?
เรียน Claude Method — วิธีคิดและลงมือใช้ Claude/AI กับงานจริง ตั้งแต่วันแรก
📍 โพสต้นฉบับบน Facebook: AI กับ Peesamac