วิศวกรของ Netflix ทำเครื่องมือลดบิล AI ได้ 60-95%…

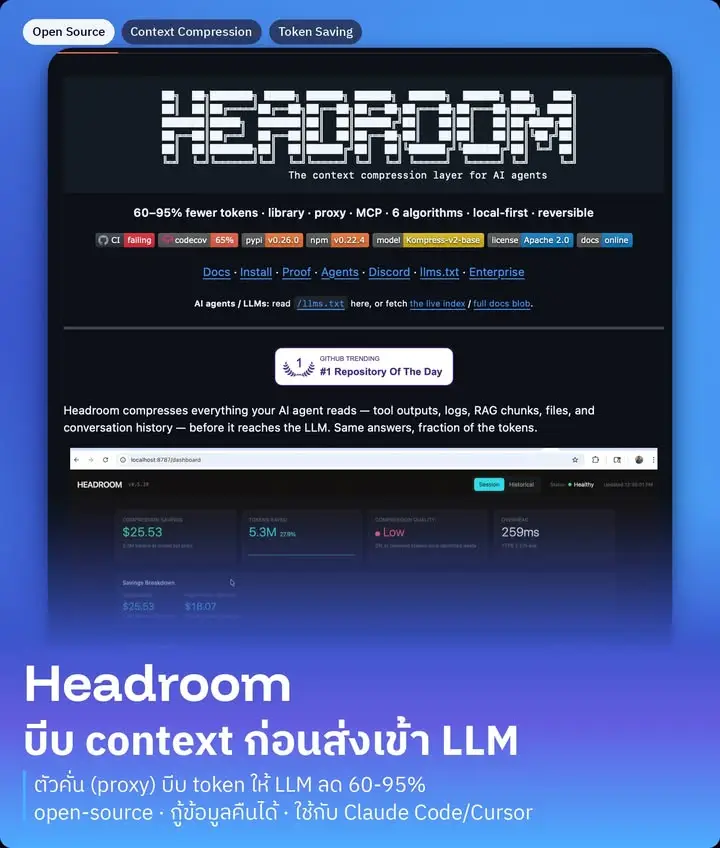
เครื่องมือตัวนี้ชื่อ Headroom กำลังมาแรงมากบน GitHub (ตอนนี้ 30,000+ ดาว ขึ้นเป็น Repository อันดับ 1 ที่คนพูดถึงในวันนั้น) เป็น open-source ฟรี ใช้ License Apache 2.0 ที่เปิดให้เอาไปต่อยอดได้สบายๆ
คนที่สร้างคือ Tejas Chopra วิศวกรอาวุโส (Senior Engineer) ที่ Netflix แต่ต้องเคลียร์ให้ชัดก่อนนะครับว่ามันเป็น side project ส่วนตัวของเขา ไม่ใช่ผลิตภัณฑ์ official ของ Netflix ที่น่าสนใจคือสำนักข่าวสายเทครายงานว่า หลายทีมใน Netflix เอา Headroom ไปใช้จริงภายในแล้ว ช่วยกดต้นทุน token ลงได้ — เลยพอเชื่อได้ว่าไอเดียนี้ไม่ได้อยู่แค่บนกระดาษ
แล้วมันคืออะไร?
ลองนึกภาพว่าทุกครั้งที่เราคุยกับ AI หรือให้ agent ไปทำงาน มันต้องส่งข้อมูลกองโตเข้าโมเดล ทั้ง log, ผลลัพธ์จาก tool, โค้ดทั้งไฟล์, ประวัติแชตยาวๆ ทุกตัวอักษรที่ส่งเข้าไป = token = เงินที่เราจ่าย
Headroom ทำตัวเป็น "ตัวคั่น" (proxy / compression layer) นั่งอยู่ระหว่างแอพของเรากับ LLM แล้วบีบอัดทุกอย่างให้เล็กลงก่อนส่งเข้าโมเดล จุดที่น่าสนใจคือมันไม่ได้ "สรุปทิ้ง" แบบ summarize ทั่วไป แต่เป็นการบีบแบบ reversible (กู้คืนได้) — โมเดลเห็นเวอร์ชันย่อ แต่ถ้าต้องการตัวเต็มเมื่อไหร่ มันเรียกข้อมูลฉบับเต็มกลับมาได้ (project เรียกระบบนี้ว่า Compress-Cache-Retrieve) เลยไม่ใช่การตัดข้อมูลทิ้งแบบเสี่ยงๆ
ตัวเลขที่ project เคลมไว้ (เป็น benchmark ของทีมเขาเอง ยังไม่ใช่ผลทดสอบจากคนนอกนะครับ ทุกคนเอาไว้พิจารณาประกอบ):
- ลด token ได้ราว 60-95% แล้วแต่งาน
- ยกตัวอย่างเคส debug ระบบจริง จาก 10,144 token เหลือ 1,260 (ลดไป ~88%) แต่ข้อความ FATAL สำคัญยังอยู่ครบ
- เคสค้นโค้ดลดจาก 17,765 เหลือ 1,408 token (~92%)
- เคลมว่าความแม่นยำแทบไม่ตก เช่นบน benchmark คณิตศาสตร์ GSM8K วัดได้ ±0.000
ที่ผมว่าโดนใจสายเราคือ มันใช้กับ Claude Code, Cursor, GitHub Copilot และ client อะไรก็ตามที่เป็นแบบ OpenAI-compatible ได้เลย ติดตั้งง่ายมาก แค่ pip install แล้วเปลี่ยน base URL ก็ใช้ได้โดยแทบไม่ต้องแก้โค้ด
แต่ honest กันตรงๆ — มันยังเป็น v0.x อยู่ (ตอนเขียน v0.26.0) ยังถือว่า early stage นะครับ ทีมเขาเองก็ยอมรับว่าบาง workload ที่ข้อมูลรกๆ เช่น log จาก CI ที่มี noise เยอะ การบีบอาจทำให้รายละเอียดเล็กๆ บางอย่างหลุดไป แล้วต้องเรียกตัวเต็มกลับมาบ่อยขึ้น ดังนั้นถ้าจะลอง แนะนำเอาไปจับงานที่ไม่ critical ก่อน ดูว่าผลออกมาโอเคไหมแล้วค่อยขยับ
สรุปคือไอเดียดีมาก ตรงโจทย์คนที่เผางาน agent หนักๆ และอยากกดค่า token ลง ฟรีด้วย แค่ต้องเข้าใจว่ายังใหม่ ลองด้วยความระวังนิดนึง
ใครรัน agent เยอะๆ อยู่ ลองไปส่องดูได้ที่ github.com/chopratejas/headroom แล้วมาเล่าให้ฟังหน่อยว่ากดบิลลงได้จริงไหมครับ
อยากใช้ AI กับงานจริงเป็นระบบ?
เรียน Claude Method — วิธีคิดและลงมือใช้ Claude/AI กับงานจริง ตั้งแต่วันแรก
📍 โพสต้นฉบับบน Facebook: AI กับ Peesamac