Gemma 4 12B คือโมเดล AI ตัวใหม่จาก Google…

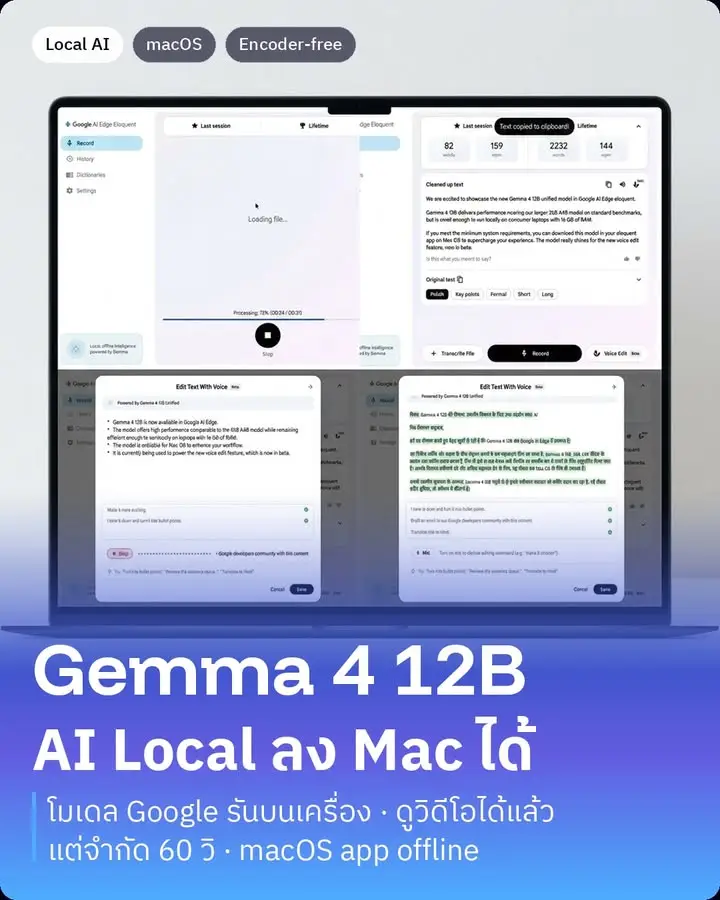
ที่ผมว่าเป็นไฮไลต์คือมันเป็นโมเดล multimodal ที่ "โยนวิดีโอเข้าไปได้แล้ว" ไม่ใช่แค่ข้อความหรือรูปนิ่ง คือเอาคลิปใส่เข้าไปแล้วถามมันได้เลยว่าในคลิปเกิดอะไรขึ้น สรุปให้หน่อย รับทั้งภาพ เสียง วิดีโอ ข้อความ ครบในตัวเดียว
แต่มีลิมิตที่ต้องรู้ก่อน วิดีโอที่ใส่ได้ตอนนี้จำกัดที่ 60 วินาที (อ่านเฟรมที่ 1 เฟรมต่อวินาที) คือเหมาะกับคลิปสั้นๆ สรุปคลิป วิเคราะห์ฉาก ไม่ใช่เอาหนังทั้งเรื่องไปให้มันดู ถ้าจะเอายาวกว่านั้นต้องไปตัดเฟรมเองก่อน
ฝั่งแอป Google ปล่อยมาสองตัว Google AI Edge Gallery (แชท วิเคราะห์ภาพ-เสียง-วิดีโอ รันโค้ดในแอปได้) กับ Google AI Edge Eloquent (พูดแล้วได้ข้อความ แก้ข้อความด้วยเสียง) ทั้งคู่รัน offline 100% บน Apple Silicon ผ่าน LiteRT จุดขายคือ private ข้อมูลไม่ออกจากเครื่อง
เบื้องหลังที่ทำให้มันเบาพอจะรันบน Mac แรม 16GB ได้ คือสถาปัตยกรรมใหม่ที่เรียกว่า encoder-free พูดง่ายๆ เมื่อก่อนโมเดลต้องมีตัวแปลงภาพ/เสียงแยกก่อนส่งเข้าสมองหลัก กินทั้งเมมและเวลา รุ่นนี้ตัดตัวแปลงทิ้ง โยนข้อมูลดิบเข้าโมเดลตรงๆ เลย ทำให้เร็วขึ้นและใช้แรมน้อยลง
จุดที่คนไทยอาจต้องเผื่อใจ คือ speech-to-text ภาษาไทยยังกลางๆ พูดไทยถอดได้บางคำแต่ยังผิดอยู่ ใครเน้นถอดเสียงไทยจริงจังตอนนี้ Whisper หรือ Typhoon ASR ยังแม่นกว่า
โดยรวมผมว่านี่คือทิศทางที่สนุก โมเดลฉลาดๆ ที่รันบนแล็ปท็อปตัวเองได้ ดูคลิปได้ ฟังเสียงได้ โดยไม่ต้องพึ่ง cloud มันเปิดทางให้ทำแอปที่ทำงานกับวิดีโอ-เสียงแบบ offline ได้อีกเยอะ ทุกคนว่าไงครับ อยากให้โมเดล local เก่งแค่ไหนถึงจะเลิกพึ่ง cloud กัน
อยากใช้ AI กับงานจริงเป็นระบบ?
เรียน Claude Method — วิธีคิดและลงมือใช้ Claude/AI กับงานจริง ตั้งแต่วันแรก
📍 โพสต้นฉบับบน Facebook: AI กับ Peesamac